Chess LLM Worker¶
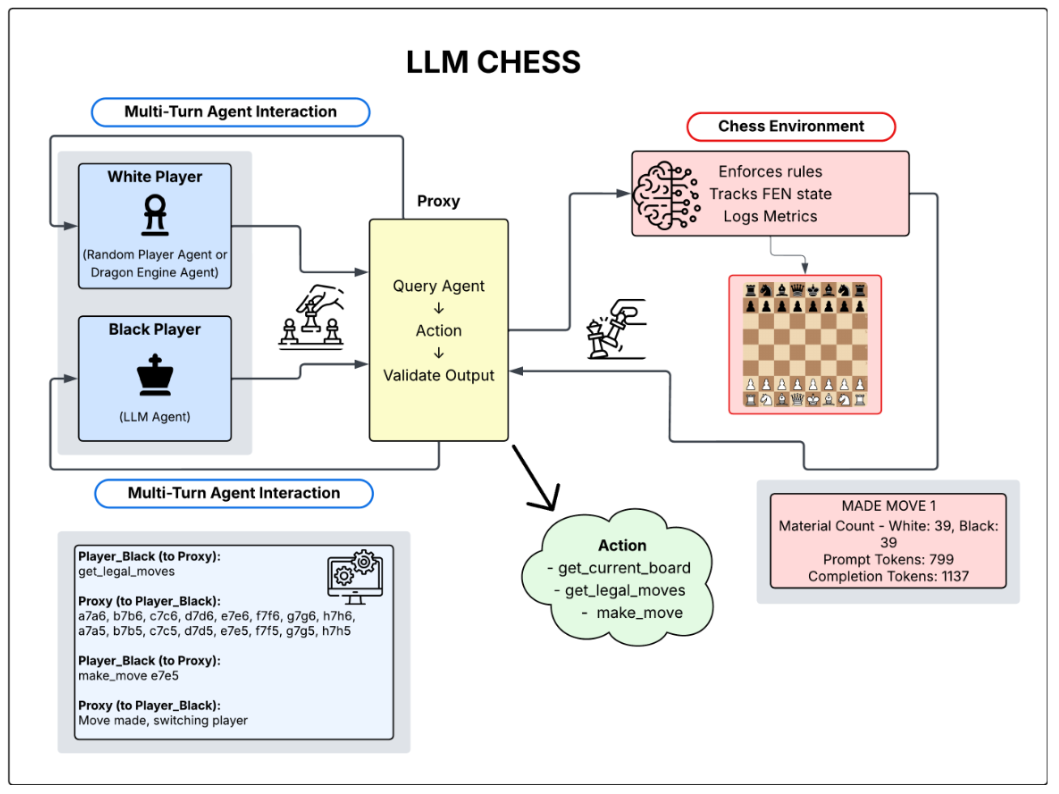
LLM Chess multi-turn agent interaction architecture (Saplin, 2025).¶
Overview¶
The Chess LLM Worker wraps the
llm_chess library to enable
LLM-driven chess play inside MOSAIC’s PettingZoo Chess environment
(chess_v6). The worker implements a multi-turn dialog protocol: on
each move the LLM can query for the current board state and legal moves
before committing to a UCI move. If the model produces an invalid move, the
worker retries with corrective feedback and, after exhausting retries, falls
back to a random legal move.
Key features:
OpenAI-compatible API: works with vLLM (local), OpenAI, and Anthropic backends via a single
client_nameswitch.Multi-turn reasoning: the LLM can issue
get_current_board,get_legal_moves, ormake_move <uci>commands across multiple dialog turns before the worker returns an action.Token tracking: every move records
input_tokensandoutput_tokensfor cost analysis.Graceful fallback: invalid moves trigger retries; on max retries a random legal move is selected automatically.
Architecture¶
The Chess LLM Worker follows the standard MOSAIC shim pattern:
3rd_party/chess_worker/
├── chess_worker/
│ ├── __init__.py # package metadata & get_worker_metadata()
│ ├── cli.py # CLI entry point (chess-worker command)
│ ├── config.py # ChessWorkerConfig dataclass
│ └── runtime.py # ChessWorkerRuntime (multi-turn LLM loop)
├── llm_chess/ # upstream library (git submodule, unmodified)
├── tests/
└── pyproject.toml
Components¶
cli.pyParses command-line arguments (
--run-id,--client-name,--model-id,--base-url,--temperature,--max-tokens,--max-retries,--max-dialog-turns,--telemetry-dir) and launches the interactive runtime.config.pyChessWorkerConfigdataclass holding all parameters:LLM settings:
client_name(vllm / openai / anthropic),model_id,base_url,api_keyGeneration:
temperature(default 0.3),max_tokens(256)Chess-specific:
max_retries(3),max_dialog_turns(10)Environment:
env_name(“pettingzoo”),task(“chess_v6”)
runtime.pyChessWorkerRuntimeimplements the multi-turn dialog loop:Receive
init_agentwithplayer_id→ set player color and system prompt.Receive
select_actionwith board state and legal moves.Build observation message, enter multi-turn LLM conversation (up to
max_dialog_turns).Parse LLM response for UCI move (
make_move <uci>).Validate against legal moves, retry on invalid.
Return action with reasoning and token statistics.
Supported Models¶
Any model accessible through an OpenAI-compatible API:
Backend |
Flag |
Example Models |
|---|---|---|
vLLM (local) |
|
Qwen2.5-1.5B-Instruct, Llama-3, Mistral |
OpenAI |
|
GPT-4o, GPT-4o-mini, o1 |
Anthropic |
|
Claude 3.5 Sonnet, Claude 3 Opus |
Action Protocol¶
The LLM communicates through structured commands in its text output:
Command |
Description |
|---|---|
|
Request the current board state (ASCII diagram) |
|
Request the list of legal UCI moves |
|
Submit a chess move in UCI notation (e.g. |
The worker parses these commands from the LLM response using regex and responds accordingly within the multi-turn loop.
JSON IPC Protocol¶
The worker communicates with the MOSAIC GUI via stdin/stdout JSON messages:
Commands:
{"command": "init_agent", "game_name": "chess_v6", "player_id": "player_0"}
{"command": "select_action", "observation": "...", "legal_moves": ["e2e4", "d2d4", "..."], "board_str": "..."}
{"command": "stop"}
Response:
{
"action_str": "e2e4",
"action_index": null,
"reasoning": "Opening with king's pawn to control the centre.",
"input_tokens": 45,
"output_tokens": 12,
"success": true
}
Configuration¶
CLI arguments:
Flag |
Default |
Description |
|---|---|---|
|
Unique run identifier |
|
|
|
LLM backend (vllm, openai, anthropic) |
|
|
Model identifier |
|
|
API base URL |
|
|
Sampling temperature |
|
|
Max output tokens per LLM call |
|
|
Max invalid move retries before random fallback |
|
|
Max conversation turns per move |
|
Directory for telemetry output |
Installation¶
# From the MOSAIC root
pip install -e "3rd_party/chess_worker[chess]"
# This installs: python-chess, pettingzoo[classic], openai
Worker Capabilities¶
Worker type |
chess |
Supported paradigms |
self_play, human_vs_ai |
Max agents |
2 |
GPU required |
No (LLM inference is remote) |
Estimated RAM |
~512 MB |