Stepping Paradigms¶
MOSAIC supports multiple stepping paradigms for different types of multi-agent interactions.
SteppingParadigm Enum¶
from enum import Enum, auto
class SteppingParadigm(Enum):
SINGLE_AGENT = auto() # Gymnasium
SEQUENTIAL = auto() # PettingZoo AEC
SIMULTANEOUS = auto() # PettingZoo Parallel / RLlib
SINGLE_AGENT¶
Standard Gymnasium interface with one agent. One observation, one action, one reward per step.
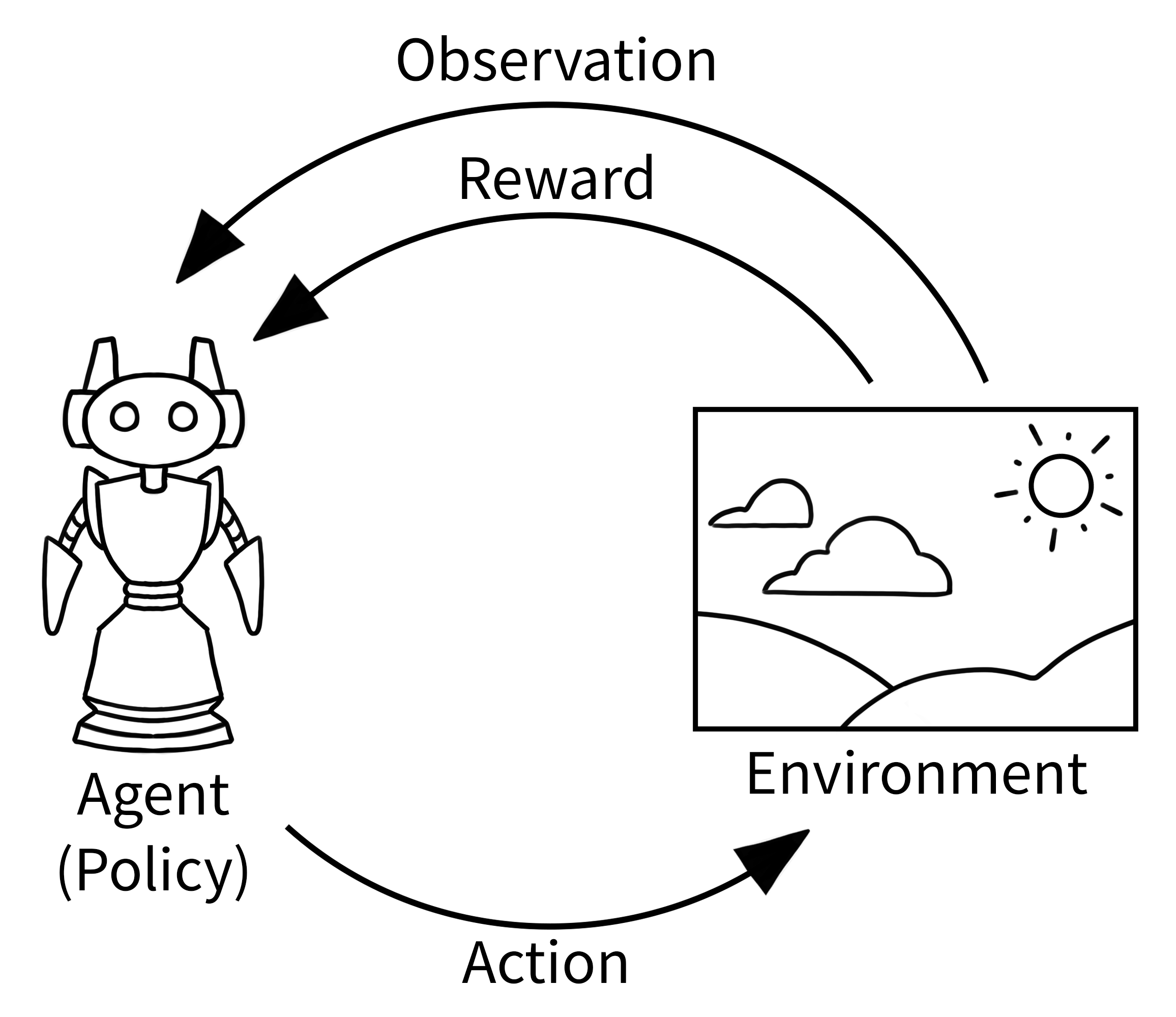
The standard agent-environment loop. (Source: Gymnasium documentation)¶
import gymnasium as gym
env = gym.make("CartPole-v1")
obs, info = env.reset()
for _ in range(1000):
action = policy(obs)
obs, reward, terminated, truncated, info = env.step(action)
Use cases: CartPole, Atari, MuJoCo continuous control
SEQUENTIAL (AEC)¶
Agents take turns one at a time, following PettingZoo’s AEC (Agent Environment Cycle) API. Each agent observes and acts before the next agent is called.
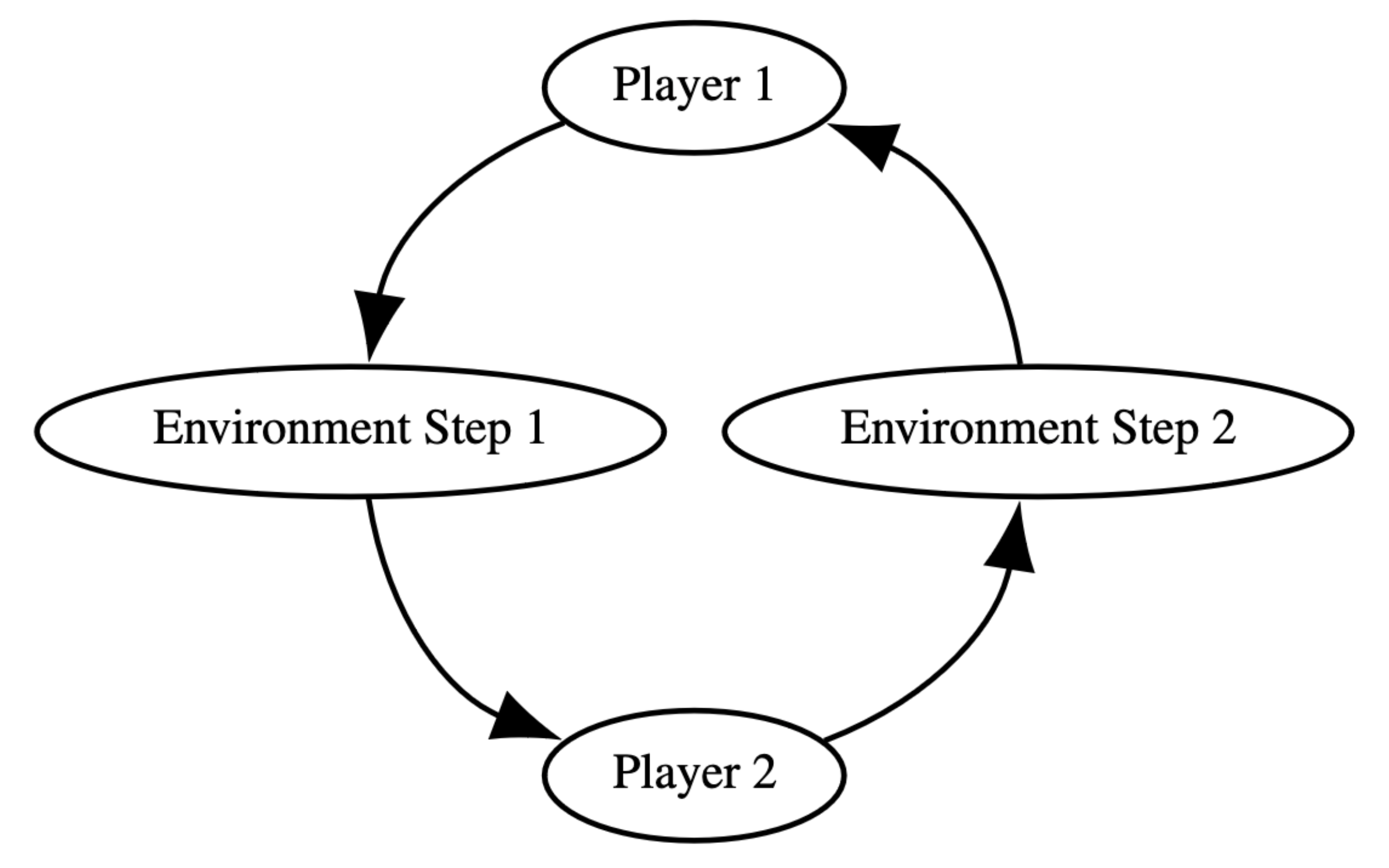
The AEC cycle: agents act sequentially. (Source: PettingZoo documentation)¶
from pettingzoo.classic import chess_v6
env = chess_v6.env()
env.reset()
for agent in env.agent_iter():
obs, reward, termination, truncation, info = env.last()
action = policy(agent, obs) if not termination else None
env.step(action)
Use cases: Chess, Go, turn-based games, OpenSpiel
SIMULTANEOUS (POSG)¶
All agents act at the same time, following PettingZoo’s Parallel API. This corresponds to a Partially Observable Stochastic Game (POSG): each agent receives only a local observation of the shared state and submits its action without seeing what other agents will do. The environment resolves all actions together in one transition.

All agents submit actions in the same step; the environment advances once all are collected. (Source: Ray RLlib documentation)¶
from pettingzoo.butterfly import pistonball_v6
env = pistonball_v6.parallel_env()
observations, infos = env.reset()
while env.agents:
actions = {agent: policy(obs) for agent, obs in observations.items()}
observations, rewards, terminations, truncations, infos = env.step(actions)
Use cases: MPE, cooperative control, competitive games