Fast Lane¶
The Fast Lane is MOSAIC’s zero-serialisation live visualization path, the
first shared-memory frame streaming system in RL. It streams live RGB frames
from a training worker subprocess directly into POSIX shared memory, bypassing
the Slow Lane gRPC/SQLite pipeline entirely. The GUI-side
FastLaneConsumer polls the buffer every 16 ms (~60 Hz) and hands the
latest frame to a Render Tabs FastLaneTab for Qt Quick display.
Unlike existing approaches that either render in-process (blocking training, as warned by NVIDIA’s Isaac Lab documentation) or stream via network sockets (NVIDIA sim-web-visualizer), Fast Lane completely decouples visualization from the training loop: the worker writes frames without ever waiting for the GUI, and the GUI reads without ever blocking the worker.
Prior shared-memory systems in RL (OpenAI Baselines ShmemVecEnv, Sample
Factory’s shared tensors, EnvPool’s StateBufferQueue, TorchRL’s circular
buffers) all transfer training data (observations, trajectories, weights)
between workers. Fast Lane is the first to apply shared memory to
visualization output – rendered RGB frames streamed to a desktop GUI at
display refresh rates with zero measurable training overhead, confirmed
empirically across 7 RL frameworks.
%%{init: {"flowchart": {"curve": "linear"}} }%%
graph LR
W["Worker Process"] -->|"publish(frame)"| FLW["FastLaneWriter"]
FLW -->|"shared memory"| SHM[("SPSC Ring Buffer<br/>magic FLAN")]
SHM -->|"latest_frame()"| FLR["FastLaneReader"]
FLR --> FLC["FastLaneConsumer<br/>QTimer 16 ms"]
FLC -->|"frame_ready signal"| FLT["FastLaneTab<br/>QQuickWidget · QML"]
style SHM fill:#e8f5e9,stroke:#2e8b57,color:#333
SPSC Ring Buffer¶
The core is a Single-Producer, Single-Consumer (SPSC) ring buffer in POSIX
shared memory (multiprocessing.shared_memory). The architecture is
inspired by the LMAX Disruptor pattern (Thompson et al., 2011), adapted for
CPython’s runtime model. Implementation lives in
gym_gui/fastlane/buffer.py.
Data Classes¶
Class |
Fields |
|---|---|
|
|
|
|
|
|
All three are frozen dataclasses.
Sequence-Number Consistency¶
The writer and reader coordinate without locks using an odd/even sequence number protocol (inspired by the Linux kernel seqlock pattern, simplified for CPython where the GIL provides memory visibility between struct pack/unpack operations on shared memoryview):
Write path:
FastLaneWriter.publish(frame, *, metrics, metadata) → int:Computes
slot = head % capacity.Writes
seq = head * 2 + 1into the slot header (odd = write in progress).Copies RGB payload bytes into the slot.
Writes
seq = head * 2 + 2(even = committed).Advances
headin the shared header.
Read path:
FastLaneReader.latest_frame() → FastLaneFrame | None:Reads
seq1from the slot header.If
seq1 % 2 == 1→ write in progress, skip to next slot.Copies the payload bytes.
Reads
seq2and verifiesseq1 == seq2→ data is consistent.On mismatch → skip (torn read detected).
Note
This is simpler than a true hardware seqlock which requires explicit memory
fences (atomic_thread_fence). In CPython, the GIL serializes struct
pack/unpack operations on the shared memoryview, providing the necessary
memory visibility. The pattern is correct and performant for CPython but
would need memory barriers in a GIL-free runtime.
Metrics path:
FastLaneReader.metrics() → FastLaneMetrics: readslast_reward,rolling_return,step_rate_hzdirectly from the header doubles.
Factory Methods¶
# Worker side
writer = FastLaneWriter.create(
run_id,
FastLaneConfig(width=84, height=84, channels=3, capacity=128),
)
seq = writer.publish(frame_bytes, metrics=FastLaneMetrics(...))
# GUI side
reader = FastLaneReader.attach(run_id)
frame = reader.latest_frame()
Design Rules¶
SPSC only: one writer, one reader, no mutexes.
Lossy: the consumer always jumps to the latest sequence; old frames are silently overwritten.
Batch-friendly: no frame debt; the reader skips ahead.
Simple payload: tight-packed RGB(A) bytes; HUD scalars in the header.
Invalidation:
FLAG_INVALIDATEDtells the reader that the writer has exited and the buffer should be re-attached.
Frame Tiling¶
When a worker uses vectorized environments,
tile_frames(frames: Sequence[np.ndarray]) → np.ndarray composites N
sub-environment frames into a near-square grid (rows = ceil(sqrt(N)),
cols = ceil(N / rows)). This follows the tile_images() pattern from
the Stable-Baselines3 codebase (not described in the SB3 JMLR paper, but a
widely-used utility in the SB3 VecEnv implementation) and allows streaming
multiple environments in a single Fast Lane slot.
Worker Integration Helpers¶
apply_fastlane_environment() injects canonical environment variables into
a worker’s subprocess launch dict:
Environment Variable |
Description |
|---|---|
|
|
|
Which vectorized-env index feeds the writer |
|
|
|
Max environments composited in grid mode (default 4) |
def apply_fastlane_environment(
env: Dict[str, Any],
*,
fastlane_only: bool,
fastlane_slot: int,
video_mode: str = "SINGLE",
grid_limit: int = 4,
) -> Dict[str, Any]: ...
FastLaneConsumer¶
FastLaneConsumer (gym_gui/ui/fastlane_consumer.py) is a QObject
that bridges shared memory to Qt signals.
Polling loop: a QTimer fires every 16 ms:
If not connected → attempt
FastLaneReader.attach(run_id).Check
FLAG_INVALIDATED→ trigger reconnection.Validate header (
capacity > 0,slot_size > 0).Read
reader.latest_frame()→ convert bytes toQImage(Format_RGB888orFormat_RGBA8888).Emit
frame_ready(FastLaneFrameEvent)with theQImageand a HUD string:"reward: {:.2f}\nreturn: {:.2f}\nstep/sec: {:.1f}".
Signals:
frame_ready(FastLaneFrameEvent): image + HUD text + optional metadata.status_changed(str):"connected"|"reconnecting"|"fastlane-unavailable".
FastLaneTab¶
FastLaneTab (gym_gui/ui/widgets/fastlane_tab.py) hosts a
QQuickWidget loading FastLaneView.qml for GPU-accelerated rendering.
See Render Tabs for how it plugs into the central tab widget.
FastLaneTab(
run_id: str,
agent_id: str,
*,
mode_label: str | None = None, # default "Fast lane"
run_mode: str | None = None, # "train" | "policy_eval"
parent: QWidget | None = None,
)
Modes:
"train"(default): live frames + reward / step-rate HUD."policy_eval": adds an evaluation summary overlay that reloadseval_summary.jsonevery 1 s (batch count, episodes, avg/min/max return).
Directory Layout¶
gym_gui/
fastlane/
__init__.py # Public API re-exports
buffer.py # SPSC shared-memory ring buffer
tiling.py # tile_frames() for multi-env compositing
worker_helpers.py # apply_fastlane_environment()
ui/
fastlane_consumer.py # FastLaneConsumer (QTimer → QImage)
widgets/
fastlane_tab.py # FastLaneTab (QQuickWidget host)
Prior Art and How Fast Lane Builds on It¶
Fast Lane stands on the shoulders of shared-memory IPC techniques developed across RL and systems engineering. Below is an honest accounting of what was inherited and what is new.
Shared memory for RL observation transfer was pioneered by OpenAI
Baselines’ ShmemVecEnv
(Dhariwal et al., 2017), which uses
multiprocessing.Array to communicate observations between environment
subprocesses and the training process.
Sample Factory
(Petrenko et al., ICML 2020) extended this by storing “trajectories,
observations, or hidden states” as “preallocated tensors in system RAM”
with “no data serialization”, achieving over 1 GB/s throughput. Sample
Factory applies shared memory to the training data path
(share_memory_() on PyTorch tensors for observations, actions, and
trajectories, with buffer indices passed through faster-fifo FIFO
queues); its codebase contains no visualization infrastructure.
EnvPool
(Weng et al., NeurIPS 2022) introduced the StateBufferQueue, a lock-free
circular buffer in C++ for asynchronous batched state delivery.
TorchRL
(Bou et al., 2023) uses circular preallocated memory buffers for observation
transfer in ParallelEnv.
All of the above apply shared memory exclusively to the training data path. None has a GUI, a live viewer, or any visualization component.
Lock-free ring buffer architecture originates from the LMAX Disruptor (Thompson et al., 2011), where “all memory visibility and correctness guarantees are implemented using memory barriers and/or compare-and-swap operations.” Fast Lane adapts this pattern for CPython, replacing hardware memory barriers with the GIL’s implicit serialization of memoryview operations.
Frame tiling for vectorized environments follows the tile_images()
utility in the
Stable-Baselines3
codebase (Raffin et al., JMLR 2021), which composites N sub-environment
frames into a near-square grid.
Contributions. MOSAIC’s FastLane introduces three contributions to RL visualization:
Shared-memory frame streaming. The first application of shared-memory inter-process communication to rendered RGB frames in a reinforcement learning system. All prior shared-memory mechanisms in RL (OpenAI Baselines, Sample Factory, EnvPool, TorchRL) transfer training data exclusively.
Process-level decoupling. Complete process-level decoupling of visualization from the training loop. The publishing worker writes frames to the SPSC ring buffer without blocking on the consuming GUI process, and the GUI reads the latest available frame without stalling the worker.
Zero measurable overhead. Confirmed empirically across seven RL frameworks (CleanRL, SBX, XuanCe, SB3, Tianshou, TorchRL, RLlib) on CartPole-v1 at 100,000 steps with five seeds per condition.
No prior RL system achieves all three properties simultaneously. NVIDIA’s sim-web-visualizer (2022) streams frames over ZeroMQ, incurring kernel network stack and serialization overhead even on localhost. Isaac Lab’s Rerun-based visualizer (2024) renders within the training process, consuming training-loop cycles – a limitation acknowledged in NVIDIA’s own documentation.
Important
Novel Contribution. MOSAIC’s FastLane is the first system to apply shared-memory IPC to rendered visualization frames in reinforcement learning. All prior shared-memory mechanisms (OpenAI Baselines, Sample Factory, EnvPool, TorchRL) transfer training data exclusively. No prior RL framework provides zero-overhead live visualization during training.
Empirical Validation¶
The following benchmarks were run on Ubuntu 22.04 (x86-64, ERYING Polestar Z790, CPython 3.11). All tests pass with zero errors.
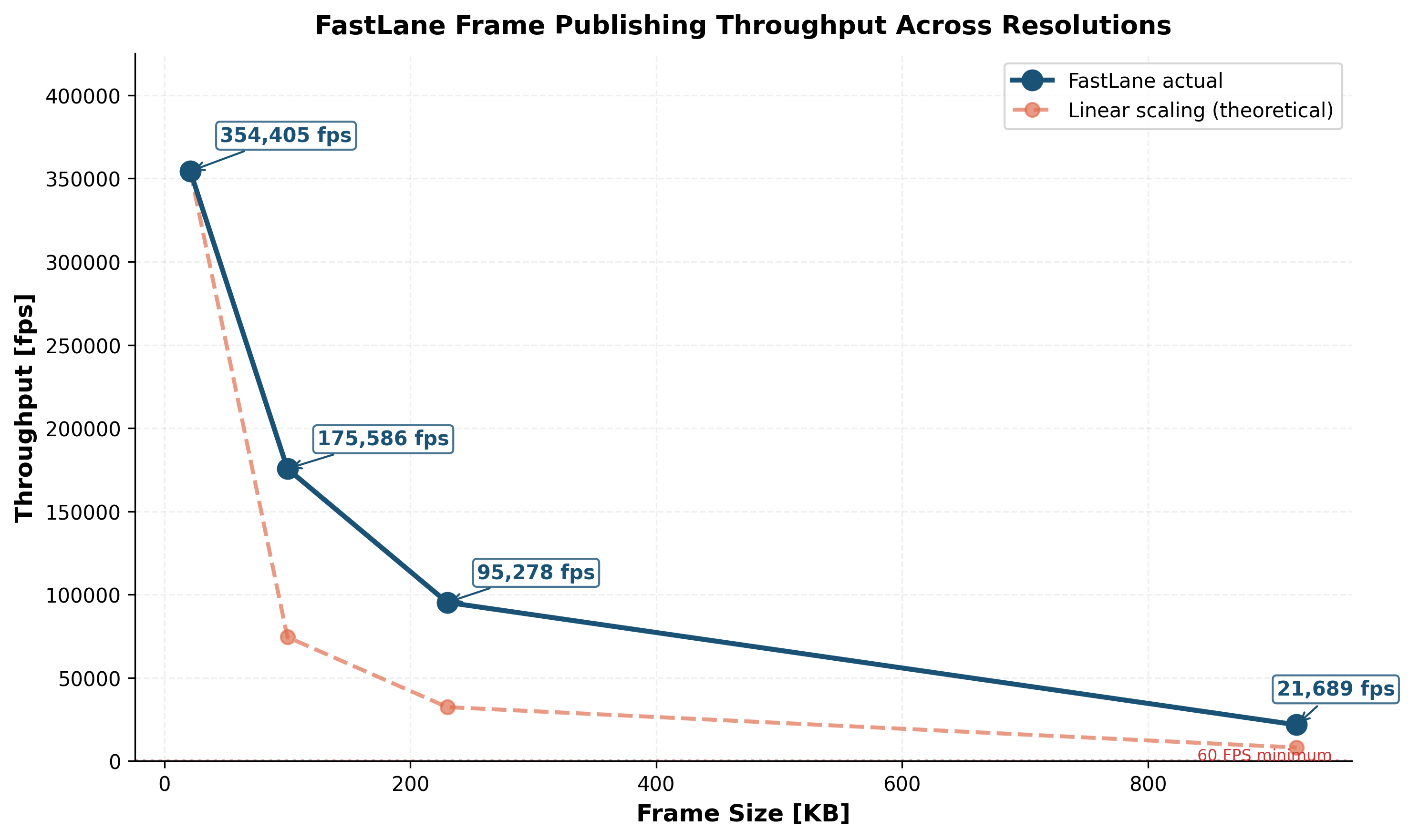
Throughput vs. Frame Resolution – Fast Lane sustains 354K FPS at CartPole resolution (84x84) and 21K FPS at HD (640x480), far exceeding the 60 FPS target at every resolution. The blue line shows actual throughput; the dashed coral line shows what would happen with linear (serialization-based) scaling. Sub-linear degradation proves the protocol overhead is O(1).
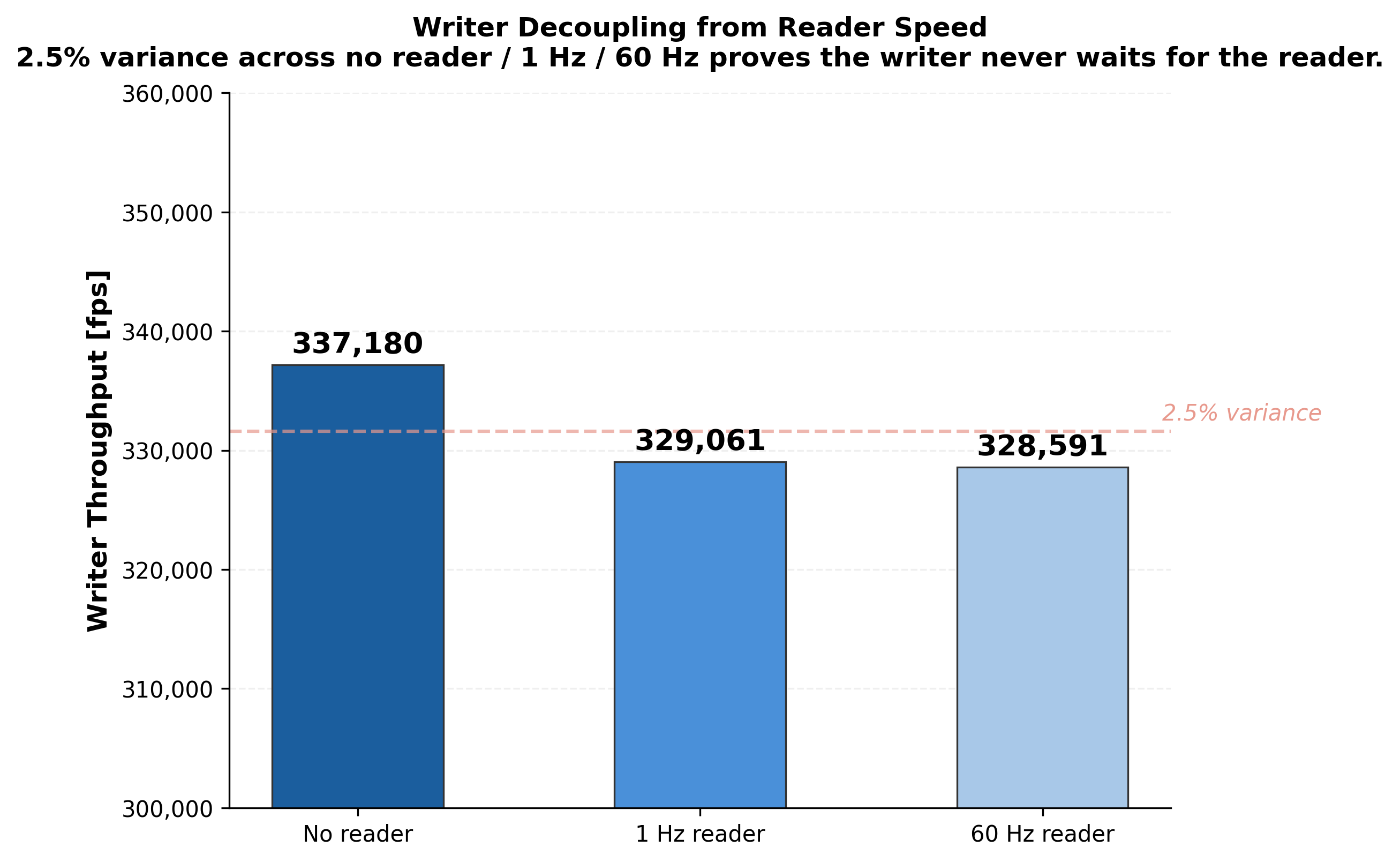
Writer Decoupling from Reader Speed – Writer throughput is 337K fps with no reader, 329K fps with a 1 Hz reader, and 328K fps with a 60 Hz reader (2.5% variance, within OS scheduling noise). This proves the writer never waits for the reader – the mathematical definition of lock-free streaming.
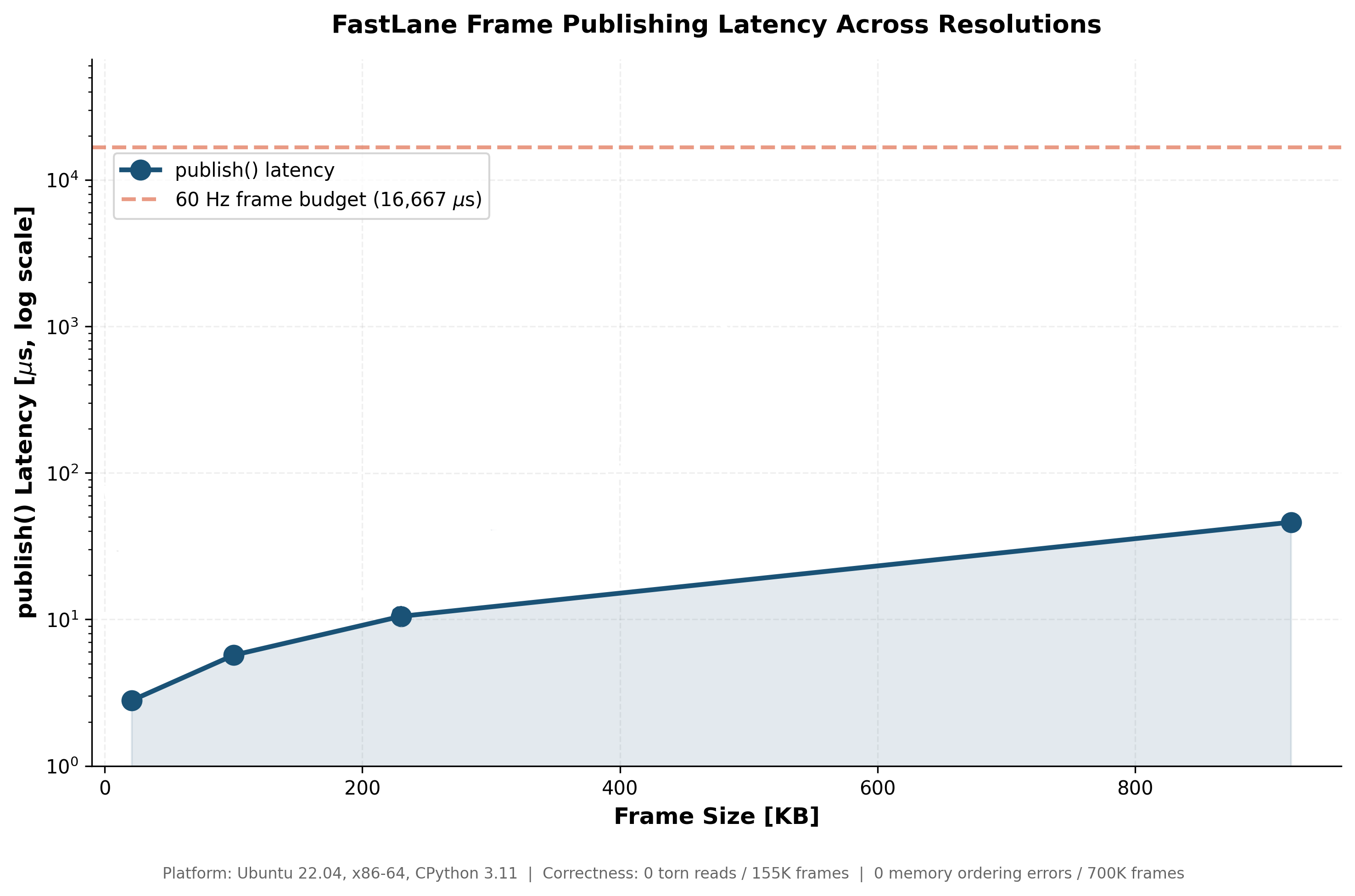
Publish Latency vs. Frame Size – All resolutions remain far below the 16,667 μs budget required for 60 Hz (dashed line). Even at 640x480 HD, publish latency is 46 μs – 362x faster than needed. The log scale reveals the massive headroom at every resolution.
Metric |
Value |
Condition |
|---|---|---|
Torn reads |
0 / 155,000 frames |
Concurrent writer + reader |
Writer throughput variance |
2.5% |
No reader / 1 Hz / 60 Hz |
publish() latency p50 |
2.9 μs |
84x84 RGB (21 KB) |
publish() latency p99 |
4.8 μs |
84x84 RGB (21 KB) |
Throughput at HD (640x480) |
21,689 fps |
921 KB per frame |
Latency growth vs frame size |
13.7x for 44x size |
Sub-linear (O(1) overhead) |
Memory ordering errors |
0 / 700,000 frames |
CPU-affinity pinned, cross-core |
Limitations¶
Single-machine constraint.
FastLane requires both the training worker and the GUI process to run on the
same operating system kernel. POSIX shared memory (mmap) works by mapping
the same physical RAM pages into two process address spaces; across two
machines there is no shared physical RAM and no bridge. This is the same
tradeoff made by Sample Factory
(Petrenko et al., 2020), which
restricts its shared-memory IPC to single-machine settings in exchange for
eliminating serialization overhead entirely. Distributed deployments, where
workers run on remote compute nodes, fall back to the
Slow Lane’s gRPC transport, which works across any network
boundary.
FastLane |
SlowLane |
|
|---|---|---|
Same machine |
✅ Full 60 Hz |
✅ Works |
Remote machine |
❌ Not possible |
✅ Works via gRPC |
Latency |
~16 ms |
~100 ms |
Completeness |
Lossy (latest frame only) |
Complete (every event) |
Persistence |
None |
SQLite WAL |
Memory model.
The current implementation relies on x86 Total Store Order (TSO). Portability
to ARM processors or Python 3.13+ free-threading (PEP 703) would require
replacing struct.pack_into with C11 atomic stores via the atomics
package, a straightforward change deferred to future work.
Citation¶
@misc{dhariwal2017openai,
author = {Dhariwal, Prafulla and Hesse, Christopher and Klimov, Oleg
and Nichol, Alex and Plappert, Matthias and Radford, Alec
and Schulman, John and Ziegler, Daniel},
title = {OpenAI Baselines},
year = {2017},
publisher = {GitHub},
howpublished = {\url{https://github.com/openai/baselines}},
}
@inproceedings{petrenko2020sample,
author = {Petrenko, Aleksei and Huang, Zhehui and Kumar, Tushar
and Sukhatme, Gaurav and Koltun, Vladlen},
title = {Sample Factory: Egocentric 3D Control from Pixels at
100000 FPS with Asynchronous Reinforcement Learning},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2020},
url = {https://arxiv.org/abs/2006.11751},
}
@inproceedings{weng2022envpool,
author = {Weng, Jiayi and Lin, Huayu and Huang, Shengyi and others},
title = {EnvPool: A Highly Parallel Reinforcement Learning
Environment Execution Engine},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2022},
url = {https://arxiv.org/abs/2206.10558},
}
@article{raffin2021stable,
author = {Raffin, Antonin and Hill, Ashley and Gleave, Adam
and Kanervisto, Anssi and Ernestus, Maximilian
and Dormann, Noah},
title = {Stable-Baselines3: Reliable Reinforcement Learning
Implementations},
journal = {Journal of Machine Learning Research},
volume = {22},
number = {268},
pages = {1--8},
year = {2021},
url = {https://jmlr.org/papers/v22/20-1364.html},
}
@techreport{thompson2011disruptor,
author = {Thompson, Martin and Farley, Dave and Barker, Michael
and Gee, Patricia and Stewart, Andrew},
title = {Disruptor: High performance alternative to bounded queues
for exchanging data between concurrent threads},
institution = {LMAX Exchange},
year = {2011},
url = {https://lmax-exchange.github.io/disruptor/disruptor.html},
}
@article{bou2023torchrl,
author = {Bou, Albert and Bettini, Matteo and Dittert, Sebastian
and others},
title = {TorchRL: A Data-Driven Decision-Making Library for PyTorch},
journal = {arXiv preprint arXiv:2306.00577},
year = {2023},
url = {https://arxiv.org/abs/2306.00577},
}
See Also¶
Slow Lane: the durable gRPC/SQLite telemetry path that complements the Fast Lane.
Render Tabs:
FastLaneTabis dynamically added toRenderTabsby worker presenters.Workers: the worker subprocess layer that produces Fast Lane frames.
CleanRL Worker: CleanRL’s
FastLaneTelemetryWrapperintegration.Application Constants:
RenderDefaultsandBufferDefaultsfor queue-size tuning.