MOSAIC¶

A Unified Platform for Cross-Paradigm Agent-Mixing and Human-AI Collaboration
MOSAIC is a visual-first platform that enables researchers to configure, run, and compare experiments across RL, LLM, VLM, and human decision-makers in the same multi-agent environment. Different paradigms like tiles in a mosaic come together to form a complete picture of agent performance.
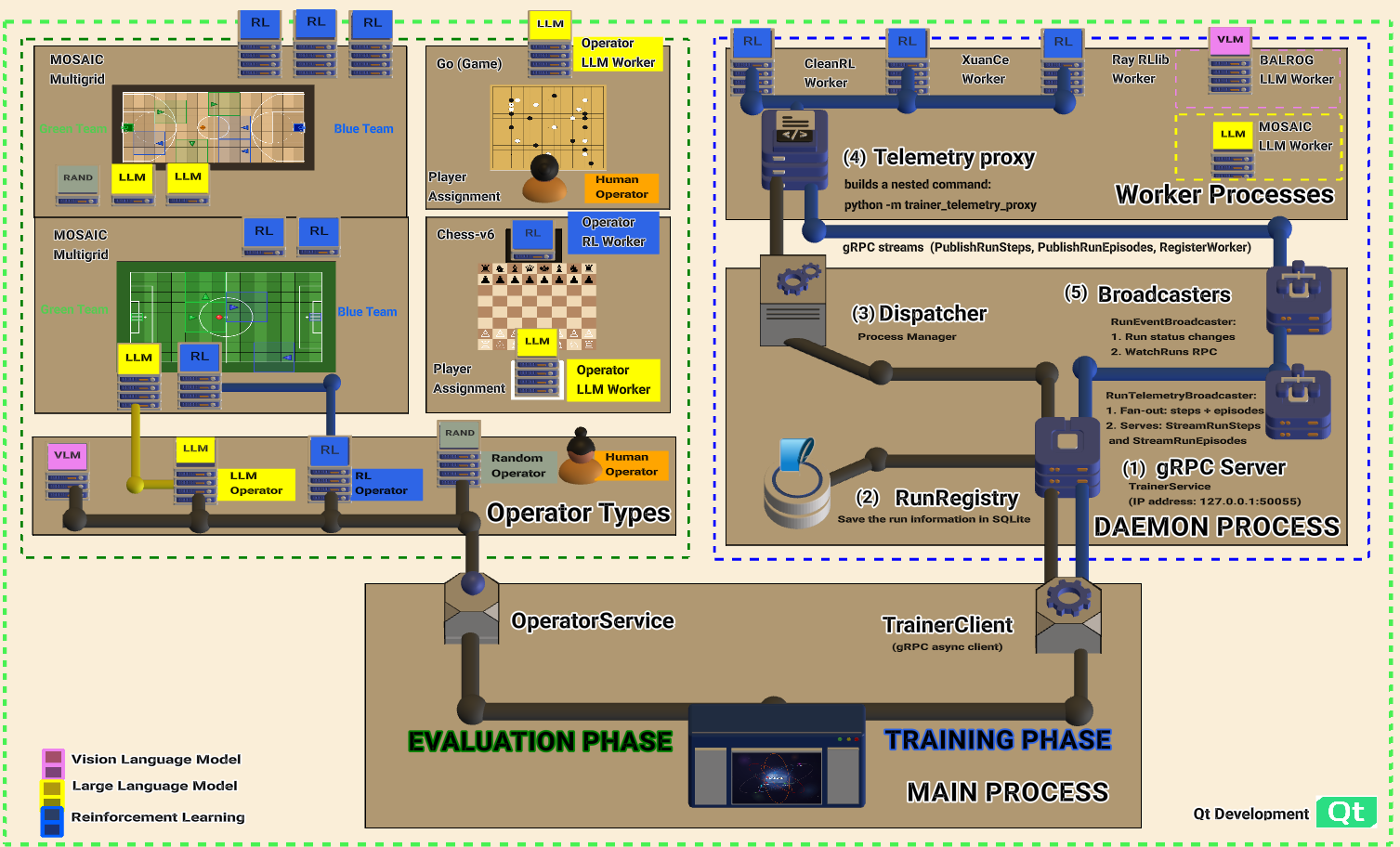
The architecture shows the Evaluation Phase (operators containing workers), Training Phase (TrainerClient, TrainerService, Workers), Daemon Process (gRPC Server, RunRegistry, Dispatcher, Broadcasters), and Worker Processes (CleanRL, XuanCe, Ray RLlib, BALROG).¶
MOSAIC provides two evaluation modes designed for reproducibility:
Manual Mode Side-by-side lock-step evaluation with shared seeds. See Operators & Evaluation Modes and Slow Lane (Render View).
Manual Mode: side-by-side comparison where multiple operators step through the same environment with shared seeds, letting researchers visually inspect decision-making differences between paradigms in real time.
Script Mode: Automated batch evaluation with deterministic seed sequences. See IPC Architecture and Runtime Logging.
Script Mode: automated, long-running evaluation driven by Python scripts that define operator configurations, worker assignments, seed sequences, and episode counts. Scripts execute deterministically with no manual intervention, producing reproducible telemetry logs (JSONL) for every step and episode.
All evaluation runs share identical conditions: same environment seeds, same observations, and unified telemetry. Script Mode additionally supports procedural seeds (different seed per episode to test generalization) and fixed seeds (same seed every episode to isolate agent behaviour), with configurable step pacing for visual inspection or headless batch execution.
Why MOSAIC?¶
Today’s AI landscape offers powerful but fragmented tools: RL frameworks (CleanRL, RLlib, XuanCe), language models (GPT, Claude), and robotics simulators (MuJoCo). Each excels in isolation, but no platform bridges them together under a unified, visual-first interface.
MOSAIC provides:
Visual-First Design: Configure experiments through an intuitive PyQt6 interface, Almost no code required.
Heterogeneous Agent Mixing: Deploy Human(Agent), RL, and LLM agents in the same environment
Resource Management & Quotas: GPU allocation, queue limits, credit-based backpressure, health monitoring.
Per-Agent Policy Binding: Route each agent to different workers via
PolicyMappingService.Worker Lifecycle Orchestration: Subprocess management with heartbeat monitoring and graceful termination.
Human vs Human: Two human players competing via dedicated USB keyboards. See Human Control and Multi-Keyboard Support (Evdev).
Random Agents: Baseline agents across 28 environment families. See MOSAIC Random Worker and Supported Environments.
Heterogeneous Multi-Agent Ad-Hoc Teamwork in Adversarial Settings: Different decision-making paradigms (RL, LLM, Random) competing head-to-head in the same multi-agent environment. See Heterogeneous Decision-Maker.
Homogeneous Teams: Random vs LLM: Two homogeneous teams (all-Random vs all-LLM) competing in the same multi-agent environment. See Homogeneous Decision-Makers.
Agent-Level Interface and Cross-Paradigm Evaluation¶
Agent-Level Interface. Existing infrastructure lacks the ability to deploy
agents from different decision-making paradigms within the same environment.
The root cause is an interface mismatch: RL agents expect tensor
observations and produce integer actions, while LLM agents expect text prompts
and produce text responses. MOSAIC addresses this through an operator
abstraction that forms an agent-level interface by mapping workers to agents:
each operator, regardless of whether it is backed by an RL policy, an LLM, or
a human, conforms to a minimal unified interface
(select_action(obs) → action). The environment never needs to know what
kind of decision-maker it is communicating with. This is the agent-side
counterpart to what Gymnasium did for
environments: Gymnasium standardized the environment interface
(reset() / step()), so any algorithm can interact with any environment;
MOSAIC’s Operator Protocol standardizes the agent interface, so any
decision-maker can be plugged into any compatible environment without modifying
either side.
Cross-Paradigm Evaluation. Cross-paradigm evaluation is the ability to deploy decision-makers from different paradigms (RL, LLM, VLM, Human, scripted baselines) within the same multi-agent environment under identical conditions, and to produce directly comparable results. Both evaluation modes described above (Manual Mode and Script Mode) guarantee that all decision-makers face the same environment states, observations, and shared seeds, making this the first infrastructure to enable fair, reproducible cross-paradigm evaluation.
See Operator Concept for the full Agent-Level Interface specification, Heterogeneous Decision-Maker for the research gap and design rationale, and IPC Architecture for Manual Mode and Script Mode implementation details.
Policy Mappings for Heterogeneous Multi-Agent Systems¶
Heterogeneous multi-agent systems require each agent to be configured independently while sharing resources where appropriate. MOSAIC enables this through flexible policy mappings: one-to-one (independent policies) and one-to-many (shared policies via link groups).
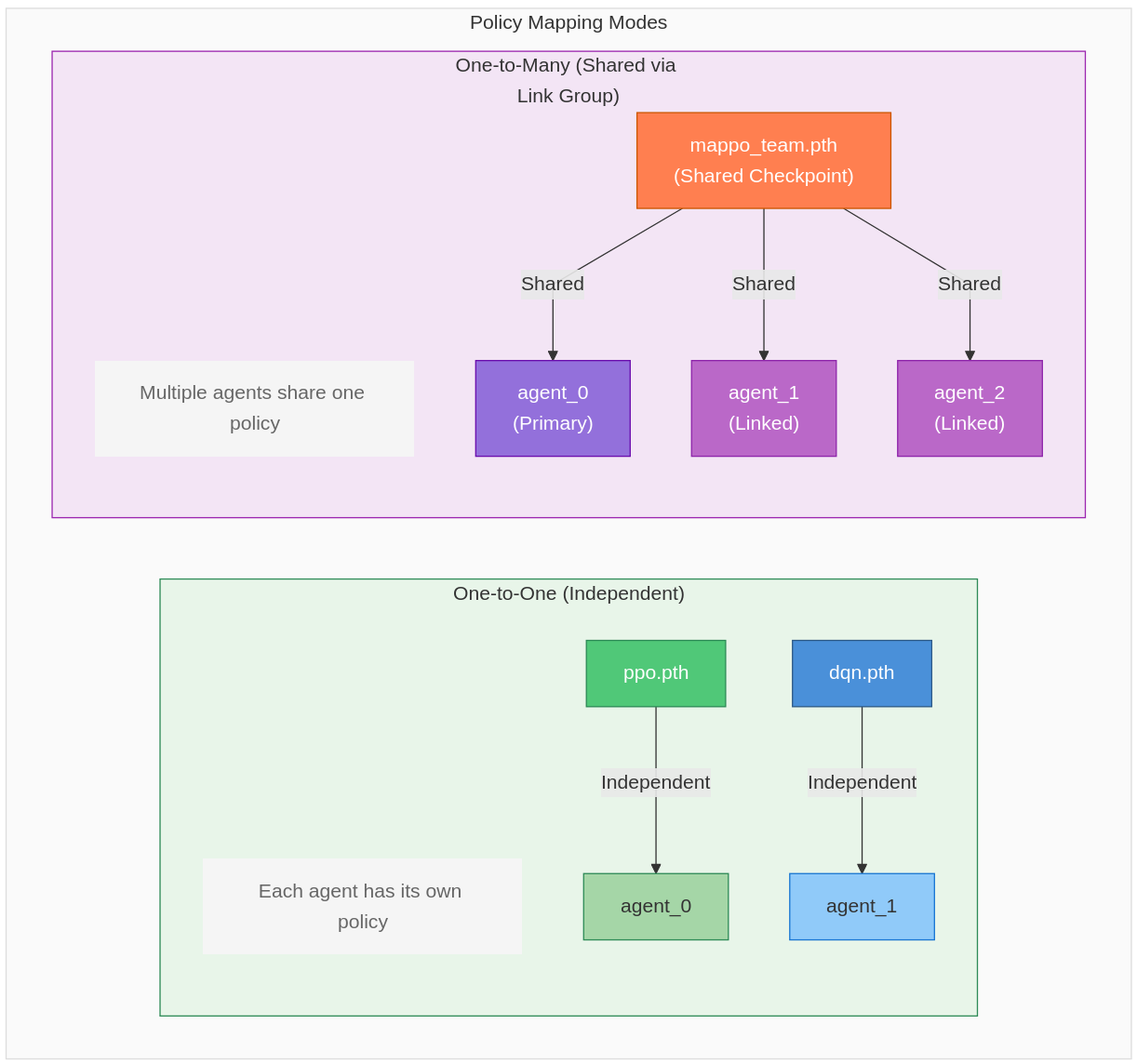
One-to-One (independent policies) and One-to-Many (shared policies via link groups).¶
Why this matters:
Without flexible policy mappings, you’re forced to choose between:
Manual configuration: Copy-paste errors, update fragility, no visual indication of sharing
Forced homogeneity: All agents must use the same worker type, no heterogeneity possible
With flexible policy mappings, you can:
Mix paradigms freely: RL, LLM, Human, Random agents in the same environment
Share resources intelligently: Link groups for RL agents trained together (MAPPO/IPPO)
Configure independently: Each agent slot has its own settings and worker type
Update automatically: Change primary agent’s policy → all linked agents update
Example: Heterogeneous 2v2 Soccer
# Green team: RL + LLM | Blue team: RL + Random
config = OperatorConfig.multi_agent(
player_workers={
"agent_0": WorkerAssignment(worker_id="xuance_worker", ...), # RL green agent mosaic_multigrid
"agent_1": WorkerAssignment(worker_id="llm_worker", ...), # LLM
"agent_2": WorkerAssignment(worker_id="xuance_worker", ...), # RL blue agent mosaic_multigrid
"agent_3": WorkerAssignment(worker_id="random_worker", ...), # Random
},
link_groups={
"operator_0_link_0": LinkGroup(
primary_agent="agent_0",
linked_agents=["agent_2"], # Agents 0 and 2 share MAPPO policy
policy_path="/path/to/mappo_1v1.pth",
),
},
)
See Policy Mappings for Heterogeneous Multi-Agent Systems for complete documentation, including a complex 3vs3 heterogeneous scenario with MAPPO + PPO + Random agents.
FastLane: Zero-Overhead Live Visualization¶
Existing RL frameworks either render in-process (blocking training) or stream via network sockets (serialization overhead). MOSAIC’s FastLane is the first shared-memory frame streaming system in RL: it streams rendered RGB frames from training worker subprocesses directly into POSIX shared memory via a lock-free SPSC ring buffer, achieving ~60 Hz live visualization with zero measurable training overhead.
Zero serialization: raw
memcpyinto shared memory, no encoding, no pipes, no sockets.Fully decoupled: the writer never waits for the reader. Empirically confirmed with 2.5% throughput variance across no-reader, 1 Hz, and 60 Hz reader conditions.
Correct: zero torn reads across 155K frames and zero memory ordering errors across 700K frames, validated by a seqlock-inspired sequence-number protocol.
Fast: 2.9 μs publish latency at CartPole resolution (84x84), 46 μs at HD (640x480), 362x faster than the 60 Hz budget.
Important
Novel Contribution. MOSAIC’s FastLane is the first system to apply shared-memory IPC to rendered visualization frames in reinforcement learning. All prior shared-memory mechanisms (OpenAI Baselines, Sample Factory, EnvPool, TorchRL) transfer training data exclusively. No prior RL framework provides zero-overhead live visualization during training.
Metric |
Value |
Condition |
|---|---|---|
Publish latency (p50) |
2.9 μs |
84x84 RGB |
Throughput at HD |
21,689 fps |
640x480 (921 KB/frame) |
Writer decoupling |
2.5% variance |
No reader / 1 Hz / 60 Hz |
Torn reads |
0 / 155,000 |
Concurrent writer + reader |
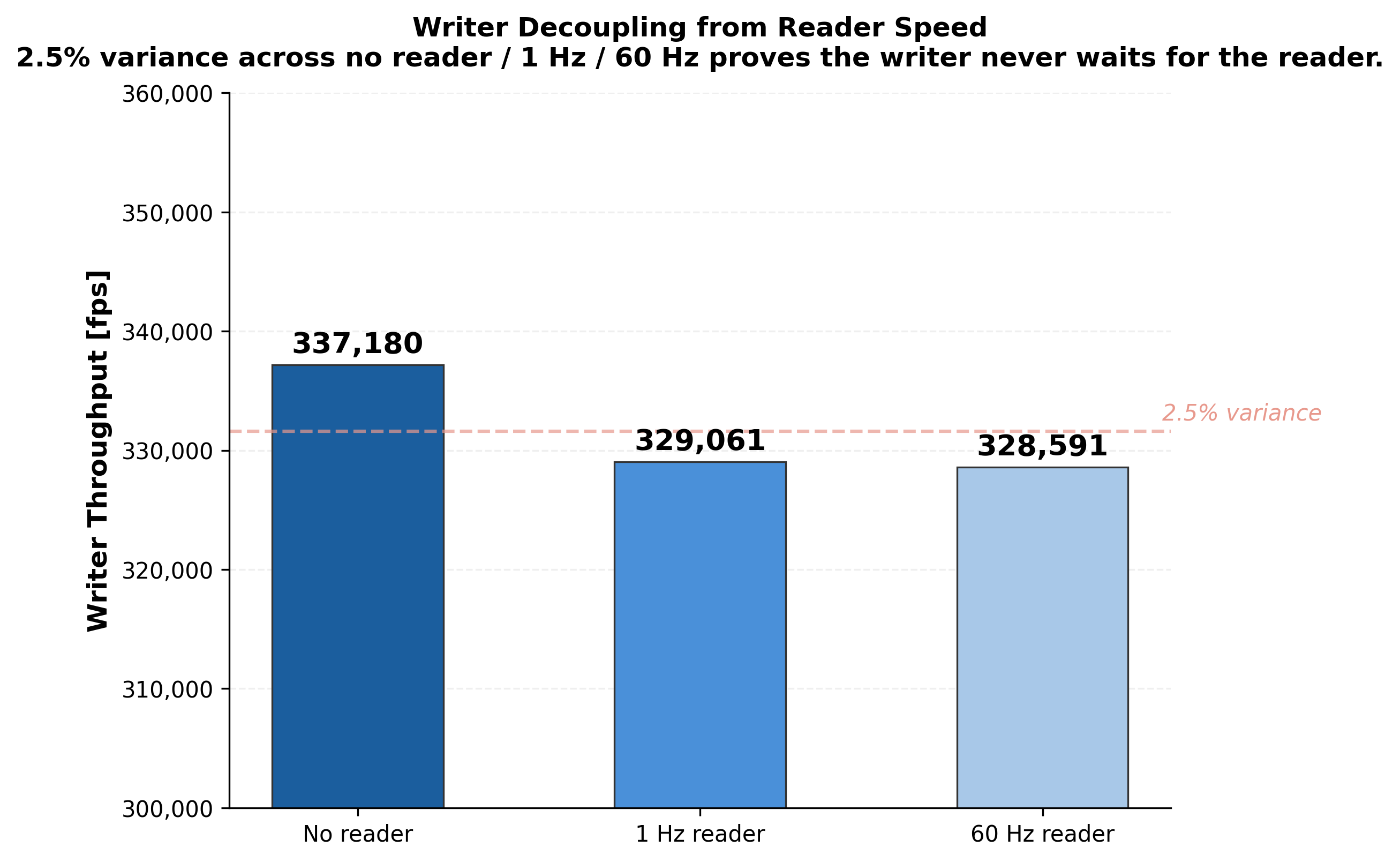
Writer throughput is independent of reader speed: 337K fps with no reader, 329K fps with a 1 Hz reader, 328K fps with a 60 Hz reader (2.5% variance).¶
Attention
FastLane requires the training worker and the GUI to run on the same machine (POSIX shared memory cannot cross network boundaries).
See Fast Lane for the full architecture, empirical benchmarks, prior art comparison, and limitations.
Note
The complementary Slow Lane is not used during training. It records high-quality human gameplay replays via gRPC and SQLite WAL storage, producing structured datasets suitable for world model training or imitation learning.
Comparison with Existing Frameworks¶
Existing frameworks are paradigm-siloed. No prior framework allowed fair, reproducible, head-to-head comparison between RL agents and LLM agents in the same multi-agent environment.
Agent-mixing: infrastructure for deploying heterogeneous agents from different paradigms in the same environment.
Platform GUI: real-time visualization during execution.
Cross-Paradigm: infrastructure for comparing different agent types (e.g., RL vs. LLM) on identical environment instances with shared random seeds for reproducible head-to-head evaluation.
Important
Novel Contribution. MOSAIC introduces an agent-level interface enabling agent-mixing across fundamentally different decision-making paradigms. This capability does not exist in any prior framework.
| System | Agent Paradigms | Infrastructure | Evaluation | Agent-mixing | ||||
|---|---|---|---|---|---|---|---|---|
| RL | LLM | VLM | Human | Framework | Platform GUI | Cross-Paradigm | ||
| RL Frameworks | ||||||||
| RLlib [1] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| CleanRL [2] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Tianshou [3] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Acme [4] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| XuanCe [5] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| OpenRL [6] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Stable-Baselines3 [7] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Coach [8] | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ |
| BenchMARL [15] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| HeMAC [25] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Overcooked-AI [26] | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| LLM/VLM Benchmarks | ||||||||
| BALROG [9] | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| TextArena [10] | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| GameBench [11] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| lmgame-Bench [12] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| LLM Chess [13] | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| LLM-Game-Bench [14] | ✗ | ✓ | ✗ | ✗ | ✓ | ◉ | ✗ | ✗ |
| AgentBench [16] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| MultiAgentBench [17] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| GAMEBoT [18] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Collab-Overcooked [19] | ◉ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| BotzoneBench [20] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| AgentGym [21] | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Cross-Paradigm Frameworks | ||||||||
| Game Reasoning Arena [22] | ✓ | ✓ | ◉ | ◉ | ✓ | ✗ | ✗ | ✗ |
| CREW [23] | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ |
| LLM-PySC2 [24] | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| MOSAIC (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
✓ Supported ✗ Not supported ◉ Partial
Experimental Configurations¶
Heterogeneous decision-making enables a systematic ablation matrix for cross-paradigm research. The following configurations illustrate the design using MOSAIC MultiGrid.
Formal Notation¶
Symbol |
Description |
|---|---|
Agent Types |
|
\(\pi^{\text{RL}}_i\) |
RL policy trained via reinforcement learning |
\(\bar{\pi}^{\text{RL}}_i\) |
Frozen RL policy (parameters \(\theta_i\) fixed; no further learning) |
\(\lambda^{\text{LLM}}_j\) |
LLM agent (large language model, text-only observations) |
\(\psi^{\text{VLM}}_k\) |
VLM agent (vision-language model, multimodal observations) |
\(h_m\) |
Human operator (interactive GUI control) |
\(\rho\) |
Uniform random baseline policy |
\(\nu\) |
No-op baseline policy (null action at every step) |
Agent Populations and Sizes |
|
\(\Pi^{\text{RL}} = \{\pi^{\text{RL}}_i\}_{i=1}^{n_{\text{RL}}}\) |
Population of RL policies of size \(n_{\text{RL}}\) |
\(\Lambda^{\text{LLM}} = \{\lambda^{\text{LLM}}_j\}_{j=1}^{n_{\text{LLM}}}\) |
Population of LLM agents of size \(n_{\text{LLM}}\) |
\(\Psi^{\text{VLM}} = \{\psi^{\text{VLM}}_k\}_{k=1}^{n_{\text{VLM}}}\) |
Population of VLM agents of size \(n_{\text{VLM}}\) |
\(\mathcal{H} = \{h_m\}_{m=1}^{n_{\text{H}}}\) |
Population of human operators of size \(n_{\text{H}}\) |
\(N = n_{\text{RL}} + n_{\text{LLM}} + n_{\text{VLM}} + n_{\text{H}}\) |
Total number of agents in the system |
Team Partitions |
|
\(\mathcal{T}_A, \mathcal{T}_B\) |
Disjoint team partitions: \(\mathcal{T}_A \cap \mathcal{T}_B = \emptyset\), \(\mathcal{T}_A \cup \mathcal{T}_B = \{1,\ldots,N\}\) |
\(n_A, n_B\) |
Team sizes: \(n_A = |\mathcal{T}_A|\), \(n_B = |\mathcal{T}_B|\), \(n_A + n_B = N\) |
Observation and Action Spaces |
|
\(\mathcal{O}^{\text{RL}} = \mathbb{R}^d\) |
RL observation space (continuous tensor) |
\(\mathcal{O}^{\text{LLM}} = \Sigma^{*}\) |
LLM observation space (strings over alphabet \(\Sigma\)) |
\(\mathcal{O}^{\text{VLM}} = \Sigma^{*} \times \mathbb{R}^{H \times W \times C}\) |
VLM observation space (multimodal: text and RGB image) |
\(\mathcal{O}^{\text{H}} = \mathbb{R}^{H \times W \times C}\) |
Human observation space (rendered RGB image) |
\(\mathcal{A} = \{1,2,\dots,K\}\) |
Discrete action space (shared after paradigm-specific parsing) |
\(\phi: \Sigma^{*} \to \mathcal{A}\) |
Deterministic parsing function mapping LLM/VLM text to actions |
Standard Self-Play vs Cross-Paradigm Transfer¶
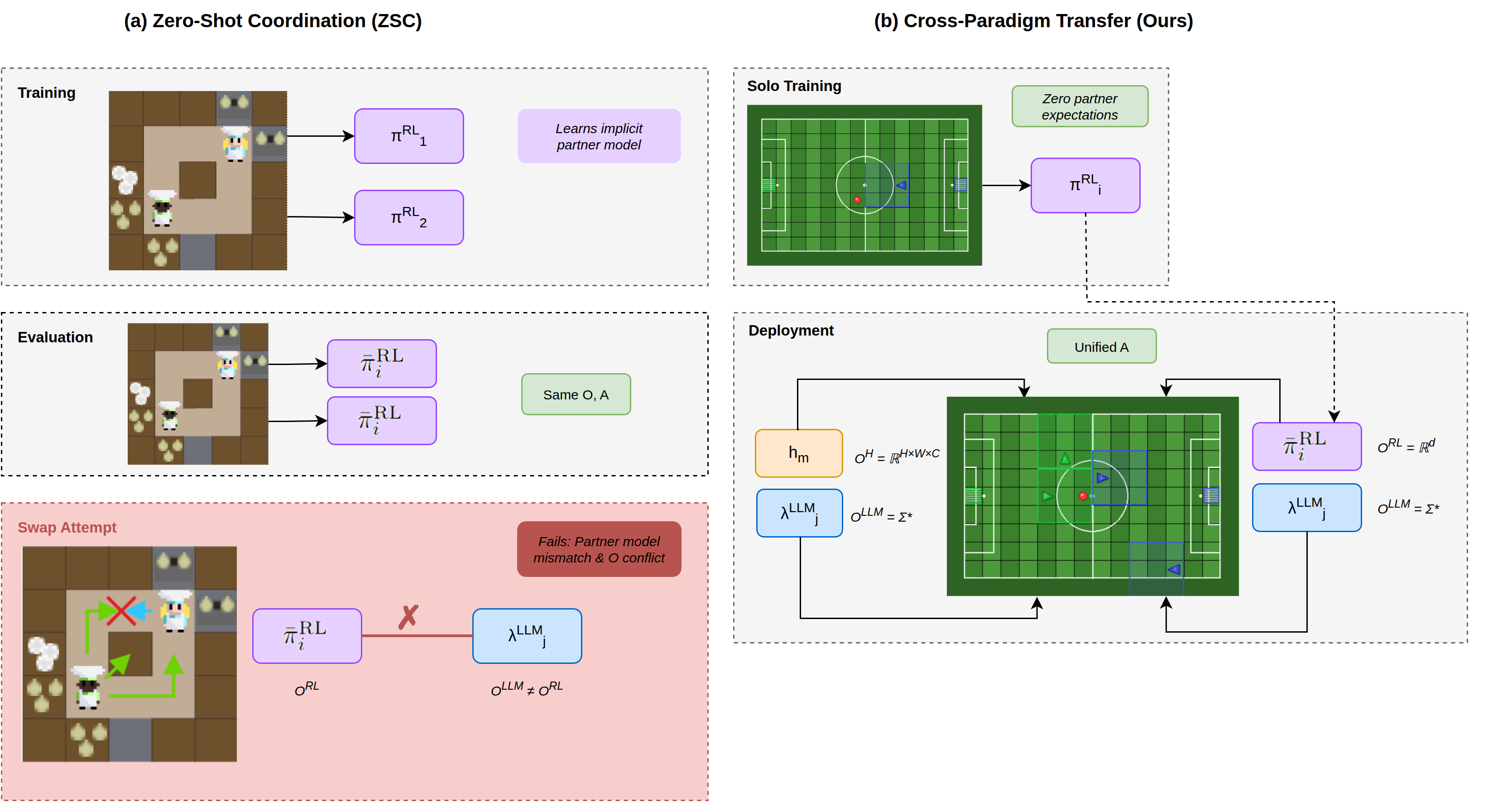
Standard Self-Play and Cross-Paradigm Transfer.¶
- (a) Standard Self-Play (Baseline): Agents \(\pi^{RL}_1\) and \(\pi^{RL}_2\) are
co-trained, learning implicit partner models that overfit to the specific environment. This approach fails the Zero-Shot Coordination (ZSC) challenge because it struggles to coordinate with unseen RL partners (who may have learned different features). It collapses when a partner is swapped across paradigms (e.g., \(\pi^{RL}\) paired with \(\lambda^{LLM}\)) due to observation space mismatches (\(\mathcal{O}^{\text{RL}} \neq \mathcal{O}^{\text{LLM}}\)) and violated behavioral expectations.
(b) Cross-Paradigm Transfer (MOSAIC): Agent \(\pi^{RL}\) is trained solo (\(N=1\), zero partner expectations), then deployed in multi-agent teams alongside
heterogeneous partners such as LLM agents \(\lambda^{LLM}\), human players \(h\), or random baselines. By eliminating co-training dependencies, agents can cooperate across paradigm boundaries using a unified action interface.
Aspect |
Standard Self-Play (Baseline) |
Cross-Paradigm Transfer (MOSAIC) |
|---|---|---|
Training |
Co-training via self-play (\(N \geq 2\)) |
Solo training (\(N=1\)) |
Partner Model |
Implicit partner model (overfitted to training partner) |
Zero partner expectations |
Generalization (RL) |
Fails with unseen RL partners (ZSC failure) |
Generalizes to unseen solo-trained RL partners |
Generalization (Cross-Paradigm) |
Fails when swapping RL ↔ LLM (Interface mismatch) |
Succeeds across paradigm boundaries |
Deployment |
Requires same-paradigm, familiar partners |
Supports RL, LLM, human, scripted agents |
Adversarial Cross‑Paradigm Matchups¶
The first set of configurations establishes single-paradigm baselines before introducing cross-paradigm matchups to measure relative performance. Let \(\mathcal{T}_A\) and \(\mathcal{T}_B\) denote disjoint team partitions with \(|\mathcal{T}_A| = n_A\) and \(|\mathcal{T}_B| = n_B\). For each team \(\mathcal{T}_k\) (\(k \in \{A,B\}\)), we define its paradigm composition as \((\Pi^{\text{RL}}_k, \Lambda^{\text{LLM}}_k, \Psi^{\text{VLM}}_k, \mathcal{H}_k)\) where \(\Pi^{\text{RL}}_k + \Lambda^{\text{LLM}}_k + \Psi^{\text{VLM}}_k + \mathcal{H}_k = n_k\).
Config |
Team A Composition |
Team B Composition |
Purpose |
|---|---|---|---|
A1 |
\(\Pi^{\text{RL}}_A = 2\) |
\(\Pi^{\text{RL}}_B = 2\) |
Homogeneous RL baseline |
A2 |
\(\Lambda^{\text{LLM}}_A = 2\) |
\(\Lambda^{\text{LLM}}_B = 2\) |
Homogeneous LLM baseline |
A3 |
\(\Psi^{\text{VLM}}_A = 2\) |
\(\Psi^{\text{VLM}}_B = 2\) |
Homogeneous VLM baseline |
A4 |
\(\Pi^{\text{RL}}_A = 2\) |
\(\Lambda^{\text{LLM}}_B = 2\) |
Cross-paradigm (RL vs LLM) |
A5 |
\(\Pi^{\text{RL}}_A = 2\) |
\(\Psi^{\text{VLM}}_B = 2\) |
Cross-paradigm (RL vs VLM) |
A6 |
\(\Lambda^{\text{LLM}}_A = 2\) |
\(\Psi^{\text{VLM}}_B = 2\) |
Cross-paradigm (LLM vs VLM) |
A7 |
\(\Pi^{\text{RL}}_A = 2\) |
\(\rho\) baseline (\(n_B = 2\)) |
Sanity check (trained vs random) |
Configurations A1-A3 measure the performance ceiling for homogeneous teams within each paradigm: RL policies trained via MARL, LLM agents reasoning via text-based decision-making, and VLM agents processing multimodal observations. Configurations A4-A6 address the central cross-paradigm research questions: under identical environmental conditions and shared random seeds, does a team of RL policies outperform teams of LLM or VLM agents, and how do LLM and VLM agents compare head-to-head? A7 serves as a sanity check, confirming that trained agents significantly outperform uniform-random baseline policies.
Cooperative Heterogeneous Teams¶
The second set of configurations examines intra-team heterogeneity by mixing paradigms within a team. These configurations test whether LLM or VLM agents (\(\lambda^{\text{LLM}}\) or \(\psi^{\text{VLM}}\)) can effectively cooperate with a frozen RL policy \(\bar{\pi}^{\text{RL}}\) that was trained without any partner model.
Config |
Team A Composition |
Team B Composition |
Research Question |
|---|---|---|---|
C1 |
\(\bar{\pi}^{\text{RL}}\), \(\lambda^{\text{LLM}}\) |
\(\bar{\pi}^{\text{RL}}\), \(\rho\) baseline |
Does \(\lambda^{\text{LLM}}\) outperform \(\rho\) as teammate? |
C2 |
\(\bar{\pi}^{\text{RL}}\), \(\lambda^{\text{LLM}}\) |
\(\bar{\pi}^{\text{RL}}\), \(\nu\) baseline |
Does \(\lambda^{\text{LLM}}\) actively contribute? |
C3 |
\(\bar{\pi}^{\text{RL}}\), \(\psi^{\text{VLM}}\) |
\(\bar{\pi}^{\text{RL}}\), \(\rho\) baseline |
Does \(\psi^{\text{VLM}}\) outperform \(\rho\) as teammate? |
C4 |
\(\bar{\pi}^{\text{RL}}\), \(\psi^{\text{VLM}}\) |
\(\bar{\pi}^{\text{RL}}\), \(\nu\) baseline |
Does \(\psi^{\text{VLM}}\) actively contribute? |
C5 |
\(\Pi^{\text{RL}}_A = 2\) |
\(\Pi^{\text{RL}}_B = 2\) |
Solo-pair baseline (no co-training) |
C6 |
\(\bar{\pi}^{\text{RL}}\), \(\lambda^{\text{LLM}}\) |
\(\Pi^{\text{RL}}_B = 2\) (co-trained) |
Can zero-shot LLM teaming match co-training? |
C7 |
\(\bar{\pi}^{\text{RL}}\), \(\psi^{\text{VLM}}\) |
\(\Pi^{\text{RL}}_B = 2\) (co-trained) |
Can zero-shot VLM teaming match co-training? |
C8 |
\(\bar{\pi}^{\text{RL}}\), \(\lambda^{\text{LLM}}\) |
\(\bar{\pi}^{\text{RL}}\), \(\psi^{\text{VLM}}\) |
LLM vs VLM as heterogeneous teammates |
All RL policies are trained solo (\(N=1\)) and frozen before deployment; LLM/VLM agents are zero-shot. Configurations C1-C2 and C3-C4 test whether LLM and VLM agents can serve as effective teammates for frozen RL policies. C5 serves as the fair comparison baseline: two independently trained solo experts paired at evaluation time. C6-C7 compare zero-shot cross-paradigm teaming against co-trained RL teams. C8 directly compares LLM and VLM agents as teammates within heterogeneous teams.
Solo‑to‑Team Transfer Design – Why Solo Training?
RL agents are trained as solo experts in single-agent environments (\(N=1\)), then deployed as teammates in multi-agent settings without any fine‑tuning. This design eliminates the co-training confound and avoids the failure modes of standard self-play.
In standard self-play, agents develop implicit partner models calibrated against other RL agents sharing the same observation space (\(\mathcal{O} = \mathbb{R}^d\)). This creates two failure modes: (1) ZSC Failure: The agent overfits to its training partner’s conventions, failing to coordinate with unseen RL agents. (2) Cross-Paradigm Failure: As shown in the figure’s “Swap Attempt” panel, replacing an RL partner with an LLM agent causes a breakdown due to observation space mismatches (\(\mathcal{O}^{\text{RL}} \neq \mathcal{O}^{\text{LLM}}\)).
By training agents in isolation (\(N=1\)), the RL policy carries zero partner expectations. This cleanly isolates the paradigm variable as the sole experimental factor, allowing true cross-paradigm coordination where the challenge is not just an unknown policy, but a fundamentally different way of perceiving and acting in the world.
For full mathematical details and further configurations, see the companion paper.
Supported Environment Families¶
MOSAIC supports 31 environment families spanning single-agent, multi-agent, and cooperative/competitive paradigms. See the full Environment Families reference for installation instructions, environment lists, and academic citations.
Family |
Description |
Example Environments |
Status |
|---|---|---|---|
Standard single-agent RL (Toy Text, Classic Control, Box2D, MuJoCo) |

|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ❌
|
|
128 classic Atari 2600 games |

|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ✅
|
|
Procedural grid-world navigation |
|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ❌
|
|
Language-grounded instruction following |
|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ❌
|
|
High-performance grid worlds with C++ backend & Vulkan GPU rendering (34 envs) |
|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ✅
|
|
Doom-based first-person visual RL |

|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
Roguelike sandbox built on NetHack (NLE) |

|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
Full NetHack roguelike game via NLE |

|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
Open-world survival benchmark |
|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
16 procedurally generated environments |

|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ❌
|
|
Rule-manipulation puzzles |
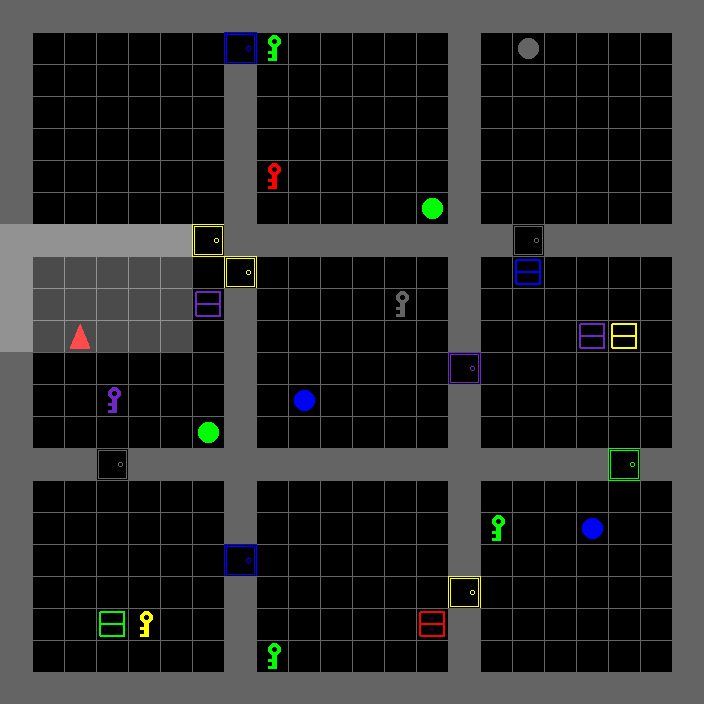
|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
Text-based interactive fiction (Microsoft Research) |

|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
JAX-accelerated logic/routing/packing (25 envs) |

|
Human-Control: ✅
Single-Agent: 📋
Multi-Agent: ❌
|
|
Quadcopter physics simulation |
|
Human-Control: ❌
Single-Agent: ✅
Multi-Agent: ✅
|
|
Turn-based board games (AEC) |

|
Human-Control: ✅
Single-Agent: ❌
Multi-Agent: ✅
|
|
Board games via DeepMind’s OpenSpiel + Shimmy (Chess, Go, Checkers) |
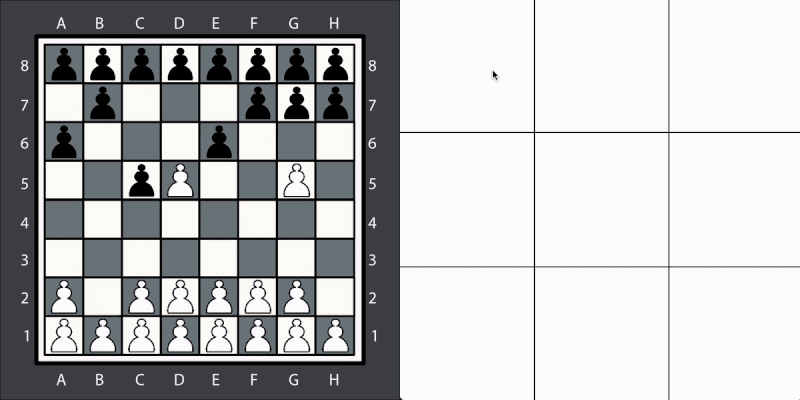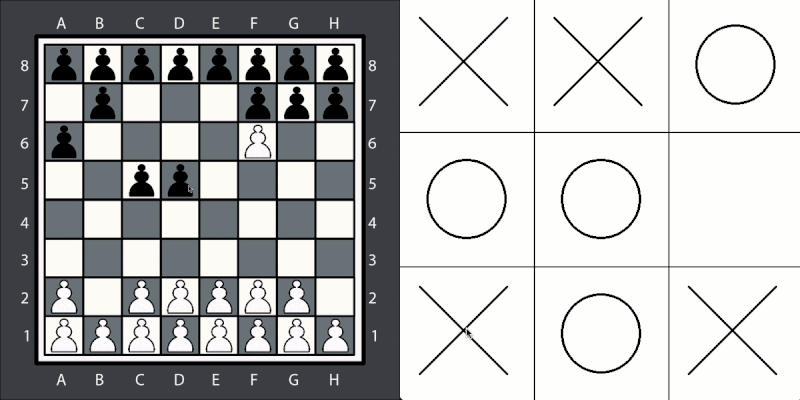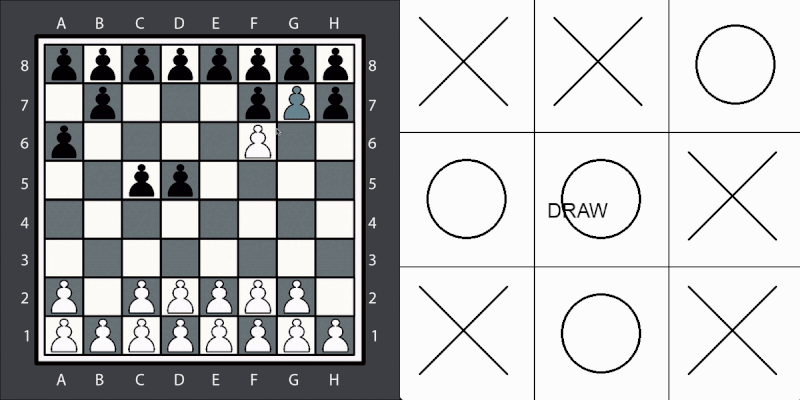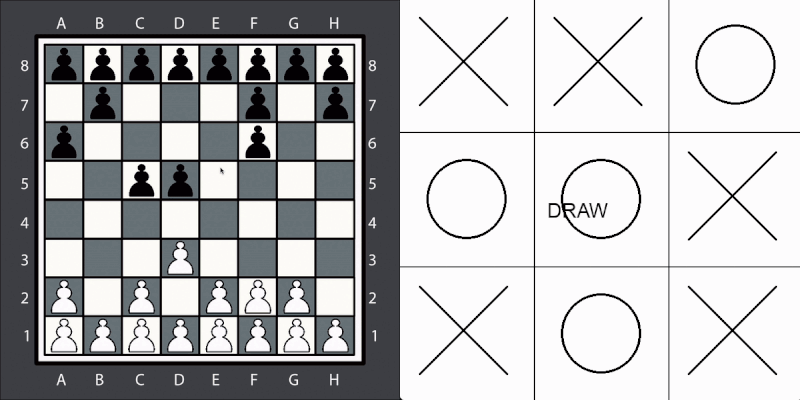
|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ❌
|
|
Competitive team sports (view_size=3) |
|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: ✅
|
|
Cooperative exploration (view_size=7) |
|
Human-Control: ✅
Single-Agent: ❌
Multi-Agent: ✅
|
|
Social multi-agent scenarios (up to 16 agents) |

|
Human-Control: ✅
Single-Agent: ❌
Multi-Agent: ✅
|
|
Cooperative cooking (2 agents) |

|
Human-Control: ✅
Single-Agent: ❌
Multi-Agent: ✅
|
|
StarCraft Multi-Agent Challenge (hand-designed maps) |
|
Human-Control: ❌
Single-Agent: ❌
Multi-Agent: ✅
|
|
StarCraft Multi-Agent Challenge v2 (procedural units) |

|
Human-Control: ❌
Single-Agent: ❌
Multi-Agent: ✅
|
|
Cooperative warehouse delivery |
|
Human-Control: ✅
Single-Agent: ❌
Multi-Agent: ✅
|
|
Heterogeneous multi-agent challenge (Quadcopters, Observers, Provisioners) |
Human-Control: 📋
Single-Agent: 📋
Multi-Agent: ✅
|
||
MuJoCo |
Continuous-control robotics tasks |

|
Human-Control: ✅
Single-Agent: ✅
Multi-Agent: 📋
|
Google Research Football (experimental) |
11-vs-11 football/soccer simulation (Google Research) |

|
Human-Control: 🚧
Single-Agent: 🚧
Multi-Agent: 🚧
|
MarLo (experimental) |
Multi-Agent RL in Minecraft (2018 MarLo Challenge) |

|
Human-Control: ✅
Single-Agent: 🚧
Multi-Agent: 🚧
|
Malmo (experimental) |
Microsoft Research AI platform built on Minecraft |
|
Human-Control: ✅
Single-Agent: 🚧
Multi-Agent: 🚧
|
Supported Workers (8)¶
CleanRL: Single-file RL implementations (PPO, DQN, SAC, TD3, DDPG, C51)
XuanCe: Modular RL framework with flexible algorithm composition and custom environments. Multi-agent algorithms (MAPPO, QMIX, MADDPG, VDN, COMA)
Ray RLlib: RL with distributed training and large-batch optimization (PPO, IMPALA, APPO)
BALROG: LLM/VLM agentic evaluation (GPT-4o, Claude 3, Gemini · NetHack, BabyAI, Crafter)
MOSAIC LLM: Multi-agent LLM with coordination strategies and Theory of Mind (MultiGrid, BabyAI, MeltingPot, PettingZoo)
Chess LLM: LLM chess play with multi-turn dialog (PettingZoo Chess)
MOSAIC Human Worker: Human-in-the-loop play via keyboard for any Gymnasium-compatible environment (MiniGrid, Crafter, Chess, NetHack)
MOSAIC Random Worker: Baseline agents with random, no-op, and cycling action behaviours across all 28 environment families
Roadmap¶
MOSAIC is actively expanding to support more diverse and complex environments, simulators, and algorithms.
Environments
Environment |
Status |
Description |
|---|---|---|
Google Research Football |
🚧 Experimental |
11-vs-11 football/soccer simulation for multi-agent RL research |
Minecraft: Malmo |
🚧 Experimental |
Microsoft Research AI platform built on Minecraft for fundamental AI research |
Minecraft: MarLo |
🚧 Experimental |
Multi-Agent RL environments for Minecraft (2018 MarLo Challenge) |
Minecraft: MineRL / Mindcraft |
📋 Planned |
Additional Minecraft-based AI research platforms |
Simulators
Simulator |
Status |
Description |
|---|---|---|
AirSim |
📋 Planned |
Microsoft Research simulator for drones and autonomous vehicles |
Godot Engine |
📋 Planned |
Free, open-source game engine for custom RL environments |
Algorithms
More algorithms coming soon, including additional multi-agent and hierarchical RL methods.
Legend: 🚧 Experimental (under active development) | 📋 Planned (on roadmap)
Citing MOSAIC¶
If you use MOSAIC in your research, please cite the following paper:
@misc{mousa2026mosaicunifiedplatformcrossparadigm,
title={MOSAIC: A Unified Platform for Cross-Paradigm Agent-Mixing and Human-AI Collaboration},
author={Abdulhamid M. Mousa and Yu Fu and Rakhmonberdi Khajiev and Jalaledin M. Azzabi and Abdulkarim M. Mousa and Peng Yang and Yunusa Haruna and Ming Liu},
year={2026},
eprint={2603.01260},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2603.01260},
}
References¶
[1] E. Liang et al., "RLlib: Abstractions for Distributed Reinforcement Learning," ICML, 2018.
[2] S. Huang et al., "CleanRL: High-quality Single-file Implementations of Deep RL Algorithms," JMLR, 2022.
[3] J. Weng et al., "Tianshou: A Highly Modularized Deep RL Library," JMLR, 2022.
[4] M. Hoffman et al., "Acme: A Research Framework for Distributed RL," arXiv:2006.00979, 2020.
[5] W. Liu et al., "XuanCe: A Comprehensive and Unified Deep RL Library," arXiv:2312.16248, 2023.
[6] S. Huang et al., "OpenRL: A Unified Reinforcement Learning Framework," arXiv:2312.16189, 2023.
[7] A. Raffin et al., "Stable-Baselines3: Reliable RL Implementations," JMLR, 2021.
[8] I. Caspi et al., "Reinforcement Learning Coach," 2017.
[9] D. Paglieri et al., "BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games," arXiv:2411.13543, 2024.
[10] G. De Magistris et al., "TextArena," 2025.
[11] D. Costarelli et al., "GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents," arXiv:2406.06613, 2024.
[12] Y. Huang et al., "lmgame-Bench: Evaluating LLMs on Game-Theoretic Decision-Making," 2025.
[13] M. Saplin, "LLM Chess," 2025.
[14] J. Guo et al., "LLM-Game-Bench: Evaluating LLM Reasoning through Game-Playing," 2024.
[15] M. Bettini et al., "BenchMARL: Benchmarking Multi-Agent Reinforcement Learning," JMLR, 2024. arXiv:2312.01472.
[16] X. Liu et al., "AgentBench: Evaluating LLMs as Agents," ICLR, 2024. arXiv:2308.03688.
[17] K. Zhu et al., "MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents," ACL, 2025. arXiv:2503.01935.
[18] Y. Lin et al., "GAMEBoT: Transparent Assessment of LLM Reasoning in Games," ACL, 2025. arXiv:2412.13602.
[19] H. Sun et al., "Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents," EMNLP, 2025. arXiv:2502.20073.
[20] L. Li et al., "BotzoneBench: Scalable LLM Evaluation via Graded AI Anchors," arXiv:2602.13214, 2026.
[21] Z. Xi et al., "AgentGym: Evolving Large Language Model-based Agents across Diverse Environments," ACL, 2025. arXiv:2406.04151.
[22] Cipolina et al., "Game Reasoning Arena: A Comprehensive Evaluation Framework for Large Language Models," arXiv:2501.00363, 2025.
[23] Y. Wang et al., "CREW: A Benchmark for Collaborative Multi-Step Reasoning and Planning," NeurIPS, 2024.
[24] X. Ma et al., "LLM-PySC2: A Benchmark for Large Language Models in StarCraft II," arXiv:2412.19668, 2024.
[25] C. Dansereau et al., "The Heterogeneous Multi-Agent Challenge," arXiv:2509.19512, 2025.
[26] M. Carroll et al., "On the Utility of Learning about Humans for Human-AI Coordination," NeurIPS, 2019.
Contents¶
Getting Started:
- Installation
- Why Modular Dependencies?
- System Requirements
- Quick Start Installation
- Dependency Architecture
- Environment Family Installation
- Worker-Specific Installation
- Special Setup: StarCraft II (SMAC / SMACv2)
- Special Setup: Local 3rd-Party Packages
- Verifying Installation
- Troubleshooting
- Platform Guides
- Next Steps
- Quickstart
Architecture:
- Overview
- Stepping Paradigms
- PolicyMappingService
- Workers
- Engines
- Actors
- Operators
- Key Principles
- Available Operators
- What Is an Operator?
- Homogeneous Decision-Makers
- Heterogeneous Decision-Maker
- Policy Mappings for Heterogeneous Multi-Agent Systems
- IPC Architecture
- Operator Lifecycle
- Developing an Operator
- Adding an Environment Family
- Step 1: Add to
ENV_FAMILIES - Step 2: Update
_auto_detect_agent_count - Step 3: Update
_get_execution_mode - Step 4: Update multi-agent guard tuples
- Step 5: Add environment creation
- Step 6: Add preview rendering
- Step 7: Add settings panel (optional)
- Environment Family Checklist
- Example:
mosaic_multigrid/ini_multigridSplit
- Step 1: Add to
- Operator Examples
Rendering:
Runtime Logs:
Human Control:
Environments:
- Environment Families
- Gymnasium
- Atari / ALE
- MiniGrid
- BabyAI
- MOSAIC MultiGrid
- INI MultiGrid
- Griddly
- ViZDoom
- Project Malmo (Microsoft Research)
- MarLo (Multi-Agent Reinforcement Learning in Malmo)
- MiniHack
- NetHack
- Crafter
- Procgen
- TextWorld
- BabaIsAI
- Jumanji
- PyBullet Drones
- PettingZoo
- OpenSpiel
- Melting Pot
- Overcooked
- SMAC v1
- SMACv2
- RWARE (Robotic Warehouse)
- HeMAC
API Reference: